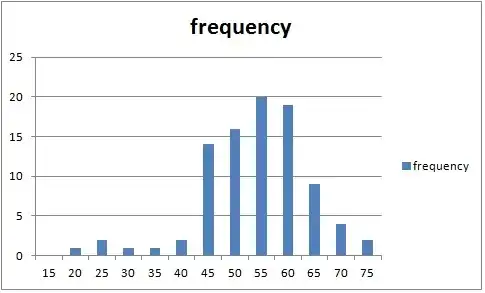
Histogram showing the frequency for test scores (range 15-75) for a total of 91 students.
Histogram showing the frequency for test scores (range 15-75) for a total of 91 students.
So this question is hard to answer given that we don't actually have your dataset and can only guess at what the data values actually are. However, based on your plot the data looks fairly normal to me (maybe a little skewed to the left) but this is subjective.
I guessed at what your data was from the plot and ran the Shapiro-Wilk test on it to test for normality. Here is what "my" data looks like:

Now, the null hypothesis under the Shapiro-Wilk test is that the data follows a normal distribution. Running the test, in R, I obtained the following results:
> shapiro.test(x)
Shapiro-Wilk normality test
data: x
W = 0.9391, p-value = 0.0002158
and so we have a p-value = 0.0002158 which is highly significant and indicates that we should reject the null hypothesis and conclude that normal distribution is probably not a good fit for this data.
Thus, based on the test, I would advise that it would be incorrect to apply tests appropriate for normal distributions to this data set.
I am posting my R code in case anyone else would like to run it or if anyone else would like to try different values for the data I constructed.
setwd("/home/dan/Desktop/")
x = c(rep(20,2),rep(25,3),rep(30,2),rep(35,2),rep(40,3),rep(45,14),rep(50,16),rep(55,20),rep(60,19),rep(65,9),rep(70,4),rep(75,3))
y = table(x)
jpeg("barplot.jpeg")
barplot(y)
dev.off()
shapiro.test(x)
With reasonably large samples, the $t$-test is pretty robust against non-normality. Lumley et al. (2002) show some simulations that suggest you're probably all right. The paper also has a nice reminder that many analyses don't actually require normally-distributed data. Normally-distributed variables, for example, are NOT necessary for regression--the residuals should be normally distributed, not the data itself.
If you remain concerned, I'd suggest trying a non-parametric test. Be aware that different tests often have different null hypotheses: the Wilcoxon-Mann-Whitney test can report a significant result (i.e., low $p$-value), even if the population means are identical, as demonstrated here by Fagerland (2012).
As an aside, I'd caution you about assessing the shape of a distribution from a single histogram. Binning artefacts can do weird things.