I'm especially interested in parsing sentences written in English (dependency or constituency). Ideally I'd like to have an estimation of how much improvement solving each of those major sources of errors would result in.
Asked
Active
Viewed 556 times
3
-
1See Table 1 of http://www.aclweb.org/anthology/P06-2006 and Table 16 of http://www.cl.cam.ac.uk/~sc609/pubs/cl07parser.pdf. These papers are old, but you can use them as your basis and follow up to referring papers that publish similar error metrics, to show you the hotspots. – prash Sep 24 '14 at 23:12
-
1Another method of benchmarking (that I'm currently using): use Stanford Parser's libraries to convert the test section of PTB's PS trees to dependencies -> Set1, and parse the raw sentences -> Set2. Compare them in as much detail as you wish. – prash Sep 24 '14 at 23:16
-
Too broad. Without explaining why you think different parsers would have related error causes this is a bad question. – curiousdannii Sep 25 '14 at 00:31
-
@curiousdannii: One parser may excel at questions, and perform badly at imperatives, another may be the opposite, even so, it seems like a fair question if one is not aware of existing benchmarking techniques. – prash Sep 25 '14 at 02:02
-
I would expect the major source of error for any kind of NLP parsing is the inherent and pervasive ambiguity. Another might be bad input with typing and spelling errors, novel abbreviations and slang, etc. At least in unedited sources such as email, text messages, Internet comments, etc. – hippietrail Sep 25 '14 at 09:47
-
@prash Thanks, nice references! I added one more as an answer. – Franck Dernoncourt Sep 26 '14 at 00:27
-
1@curiousdannii Excerpt from the reference I gave in my answer: "Some of the frequent error types that we identify are widely recognised as challenging, such as prepositional phrase (PP) attachment". It is therefore reasonable to think that different parsers would have some related error causes. – Franck Dernoncourt Sep 26 '14 at 00:30
1 Answers
4
A nice study:
Kummerfeld, Jonathan K., et al. "Parser showdown at the wall street corral: An empirical investigation of error types in parser output." Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Association for Computational Linguistics, 2012.
Abstract:
Constituency parser performance is primarily interpreted through a single metric, F-score on WSJ section 23, that conveys no linguistic information regarding the remaining errors. We classify errors within a set of linguistically meaningful types using tree transformations that repair groups of errors together. We use this analysis to answer a range of questions about parser behaviour, including what linguistic constructions are difficult for state-of-the-art parsers, what types of errors are being resolved by rerankers, and what types are introduced when parsing out-of-domain text.
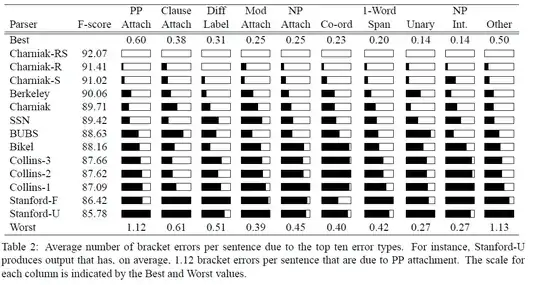
(and kudos to the authors for providing the source code)
Another nice overview from Michael Collins given in his MOOC on NLP (lecture Week 4 - Lexicalized PCFGs > Completed Evaluation of Lexicalized PCFGs (Part 2) (11:28)):
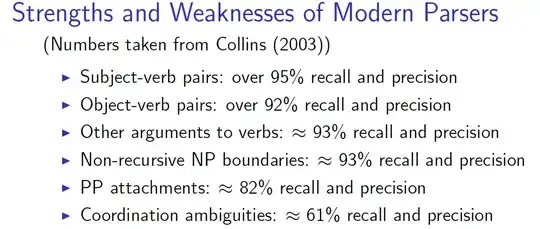
Strengths and Weaknesses of Modern Parsers (Numbers taken from Collins (2003)):
- Subject-verb pairs: over 95% recall and precision
- Object-verb pairs: over 92% recall and precision
- Other arguments to verbs: 93% recall and precision
- Non-recursive NP boundaries: 93% recall and precision
- PP attachments: 82% recall and precision
- Coordination ambiguities: 61% recall and precision
Franck Dernoncourt
- 1,588
- 2
- 12
- 35