For this 19-values series, some inconsistency exists among the methods--as expected when it comes to statistics (e.g., "no" changes detected by bcp, no breakpoint by the CUSUM and Quandt likelihood ratio tests in strucchange, no change in mean by changepoint, and three pulse-like changes by autobox). Let me give my two cents and throw some biased interpretations, which could be very wrong. Overall, I think that the different results are not directly comparable for reasons like differences in assumptions, model spaces assumed, and test statistics involved.
PURELY from an information-theoretic point of view, here is the ranking of several alternative models (no autocorrelation assumed) in terms of BIC (the smaller, the better):
M1. bic =-12.42 for the 3-pluses model by autbox (pluses at 8th,13th,& 17th)
M2. bic = -9.10 for a 2-pluses model with changes at 8th and 13th points
M3. bic = 1.601 for a mean-shift model at the 11-th point
M4. bic = 1.837 for a mean model without any changepoint
So, in terms of delta_BIC, the evidence favoring the AUTOBOX model (M1) over the no-change model (M4) is very strong. If we limit ourselves only to be the space of mean-shift models, the best model (again in terms of BIC) appears to the one-changepoint model M3 rather than the no-change model M4, although the evidence favoring M3 over M4 is rather weak. Again, this is purely interpreted in one information-theoretic criterion; the results for sure will be different if switching to classical tests.
Jumping into the Bayesian world, I interpret the bcp result a little bit differently from others. Below is the bcp result. On the first look, there is no salient peak in the probability curve, but if plotted in the finer scale, there are some small peaks and also the fitted curve differs from the a flat line, apparently due to the model averaging nature of the bayesian method. More specifically, according to the bcp output, on average the number of changepoints is 0.98, close to 1. So, my interpretation is that bcp indeed suggests an overall change in mean, but there is no strong model evidence to pinpoint an exact location so that the probability curve is spread out.

Here are also some extra results from another Bayesian changepoint detection package Rbeast my team developed (available in R, Python, and Matlab).
Below is the result with a full Bayesian model, giving an average of 0.56 changepoints.

Next is the result with an empirical Bayesian model based on BIC
library(Rbeast)
y = c(0.43, 0.45, 0.57, 0.15, 0.5, 0.33, 0.26, 0.81, 0.43, 0.48, 0.14, 0.26,-0.21, 0.27, 0.37, 0.33, 0.68, 0.15, 0.44)
o = beast(y, season='none', method='bic')
plot(o)
barplot(names.arg=0:3, o$trend$ncpPr)
On average, there is 0.746 changepoint, with the most likely location being #11th (the dashed line in the figure below), which corresponds to the best one-changepoint model M3 obtained by optimizing BIC.
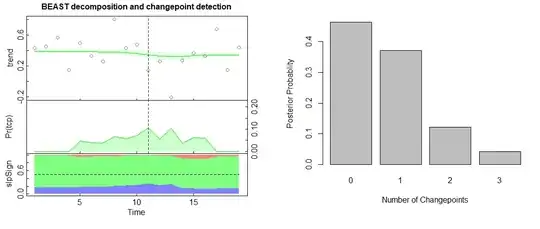
To mimic autobox, this is the result by allowing spike-like outliers without any mean changepoint allowed (i.e., tcp.minmax=c(0,0)).
o = beast(y, season='none', tcp.minmax=c(0,0), hasOutlier=TRUE)
plot(o)
barplot(names.arg=0:1, o$outlier$ncpPr)
In the Pr(tcp) subplot, the probability curve for mean changepoint is zero-valued (forced by the prior tcp.minmax=c(0,0)--no mean changepoints allowed), and the mean number of pulse-like changepoints are 0.81, with the most likely locations being #8 and #13. This corresponds to the Autobox model M1, except that #17 is missing. The missing of #17 is an implicit prior imposed inside the Rbeast program.

In some cases, even if the data is generated from a random normal independent sample, the methods may identify some "artificial" changepoints. On one hand, this is the seeming "failure" of the method or the test; more importantly, on the other hand, the data sample size is not large enough to offer good statistical power to distinguish alternative models/hypotheses.
 Note well that in general ARIMA structure has to be taken into account in time series analysis. In this case there is no provable arima structure ( autoregressive memory). It appears to me that your free software has a cost.
Note well that in general ARIMA structure has to be taken into account in time series analysis. In this case there is no provable arima structure ( autoregressive memory). It appears to me that your free software has a cost.



bcpgot a good result. The second analysis--which amounts to a bit of "data snooping" and overfitting--effectively confirmed that result by producing untenable results. If any further analysis produces "significant" changepoints, don't trust it. – whuber May 16 '14 at 14:42strucchangepackage, suggest there is no break in mean. – Khashaa Dec 28 '14 at 12:11