I have the following data over time:

that means data collected for a single variable like CPU usage in lowest, highest, and average mode over time every 5 mins (data granularity = 5mins) like the following data frame:
| | timestamp | min cpu | max cpu | avg cpu |
|---:|:--------------------|----------:|------------:|------------:|
| 0 | 2017-01-01 00:00:00 | 715147 | 2.2233e+06 | 1.22957e+06 |
| 1 | 2017-01-01 00:05:00 | 700474 | 2.21239e+06 | 1.21132e+06 |
| 2 | 2017-01-01 00:10:00 | 705954 | 2.21306e+06 | 1.20663e+06 |
| 3 | 2017-01-01 00:15:00 | 688383 | 2.18757e+06 | 1.19037e+06 |
| 4 | 2017-01-01 00:20:00 | 688277 | 2.18368e+06 | 1.18099e+06 |
I sliced the dataframe and worked on a univariate time-series data problem as follows:
| | timestamp | avg cpu |
|---:|:--------------------|------------:|
| 0 | 2017-01-01 00:00:00 | 1.22957e+06 |
| 1 | 2017-01-01 00:05:00 | 1.21132e+06 |
| 2 | 2017-01-01 00:10:00 | 1.20663e+06 |
| 3 | 2017-01-01 00:15:00 | 1.19037e+06 |
| 4 | 2017-01-01 00:20:00 | 1.18099e+06 |
I split data and applied PI (Prediction Interval) using a regression:
| | pred | lower_bound | upper_bound |
|:--------------------|------------:|--------------:|--------------:|
| 2017-01-25 00:00:00 | 1.15232e+06 | 1.12482e+06 | 1.1874e+06 |
| 2017-01-25 00:05:00 | 1.14453e+06 | 1.10052e+06 | 1.18994e+06 |
| 2017-01-25 00:10:00 | 1.14033e+06 | 1.08739e+06 | 1.20795e+06 |
| 2017-01-25 00:15:00 | 1.13669e+06 | 1.0843e+06 | 1.20252e+06 |
| 2017-01-25 00:20:00 | 1.1271e+06 | 1.06837e+06 | 1.19865e+06 |


question:
Since I'm interested in upper_bound upper prediction limit only, (if you see this image from Jason for Relationship between prediction, actual value and prediction interval) then the frame of my problem changed from PI to the simple problem of target prediction. then:
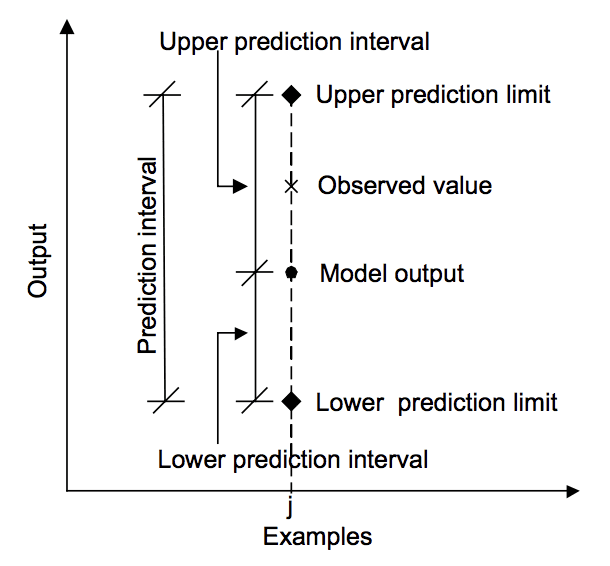{kind=link}
1. Does it mean I can easily use normal target prediction metrics ($MSE$, $MAE$, $MAPE$, $R^2 score$ ) instead of PI metrics ($PICP$, $PINC$, $ACE$, $MPIW$, $PINAW$, $PINRW$, $score$ ) to evaluate the used regression/predictive model as they treat in skforecast package? ref.
# Prediction error
# ==============================================================================
from sklearn.metrics import mean_squared_error
error_mse = mean_squared_error(
y_true = data_test['avg cpu'],
y_pred = predictions.iloc[:, 0]
)
print(f"Test error (MSE): {error_mse}")
In other words (regardless of the way is treated in skforecast package):
2. Is it fine in academics and papers that one treats the evaluation classic use of normal target prediction metrics ($MSE$, etc ) instead of PI metrics ($PICP$, etc. ) for evaluation if you are interested in only one target amongst upper\lower\targetin PI tasks?
(It would be great if you cite an example paper)
Thanks in advance
Related materials found:
- Time Series Forecasting: Prediction Intervals Estimate the range of a future observation with confidence
- Upper Bound for Size of Prediction Interval
- imbalanced regression problem + lower bound prediction + custom error weighting
- Why is the lower bound of the confidence interval of a model's error relatively constant compared to the upper bound?
- Upper & lower bound of confidence interval of mean
- Upper Bound and Lower Bound on Means when Distributions are bounded?
- Confidence Interval Upper and Lower Bound
- Confidence Intervals vs Prediction Intervals: Confusing the two can be costly. See how they differ and when to use each!
avg CPUmeasurement for our PI task and focus on its Upper bound forecast for future CPU consumption recommendation sys. – Mario Mar 10 '24 at 12:24avg cpucolumn for forecasting as well as PI. I explained everything about the situation as well as the data I had from scratch for better understanding since @picky_porpoise asked me for details. Let me know if you had queston – Mario Mar 21 '24 at 11:06