Along with Jeremy's excellent answer, I'll focus on the most relevant bit here:
I searched in the stack exchange site, and people suggest logistic
regression. However, I cannot understand why to use so complicated
mathematics when somebody can use more easy formulas?
Linear regressions estimated with the assumption of Gaussian errors should have residuals which would have a normally distributed mean and variance $N(\mu,\sigma^2)$. We immediately run into issues with this when we set boundaries to our outcome data. First, predictions will exist outside the bounds of your data and will thus be completely invalid (for example, we can't have a value of $2.5$ or $-2.5$). If we fit an OLS line to binary data, you get something like this, where you see the predicted line passes the data points and leads to this behavior:
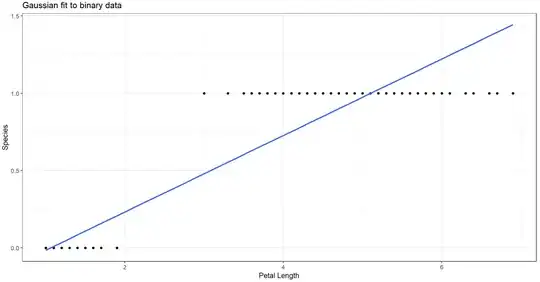
If we compare that to the sigmoid curve given by a logistic regression, you can see the line alternatively does not pass beyond the given data like before, so predictions lie completely within $0$ or $1$:

Additionally, as the mean response approaches either $0$ or $1$, the variance shrinks to zero, which will often give you bizarre diagnostic plots like these:

One of the nice properties of logistic regression is that you also get the benefit of some nice probabilities, which are listed in the sigmoid curve plot above.



But I don't understand why you would want to do this. Logistic regression is not a particularly complex model, and is designed for this.
– Peter Flom Sep 15 '23 at 22:59