It varies with context, I present one option - "directional standard deviation": compute SD separately above and below mean:

If the goal is a measure of spread of data, this can work.
Arithmetic mean isn't always best - could try median, another averaging metric, or for sparse data, "sparse mean" that I developed and applied on an audio task.
std = lambda x, x_mean: np.sqrt(1 / len(x) * np.sum((x - x_mean)**2))
x_mean = x.mean()
std_up = std(x[x >= x_mean], x_mean)
std_dn = std(x[x < x_mean], x_mean)
This was typed in a hurry and isn't polished; no consideration was given to handling x == x.mean() for equivalence with usual SD via constant rescaling, or to whether < should be <=, but it can be done, refer to @IgorF.'s answer.
Clarification
This is simply feature engineering. It has nothing to do with statistical analysis or describing a distribution. SD (standard deviation) is a nonlinear alternative to mean absolute deviation with a quadratic emphasis.
I saw a paper compute SD from 3 samples. I first-authored it and remarked it as ludicrous. Then I figure, it just functions as a spread measure, where another metric wouldn't be much better.
Whether there's better ways to handle asymmetry is a separate topic. Sometimes SD is best for similar reasons it's normally best. I can imagine it being a thresholding feature in skewed non-negative data.
Connection to question
I read the question, going off of the title and most of the body, as: "I want to use SD but want to stay non-negative". Hence, a premise is, SD is desired - making any objections to SD itself irrelevant. Of course, the question can also read as "alternatives to SD" (as it does in last sentence), but I did say, "I present one option".
More generally, any objections to my metric also hold for SD itself. There's one exception, but often it's an advantage rather than disadvantage: each number in my metric has less confidence per being derived from less data. This can be advantage since, it's more points per sub-distribution. Imagine,
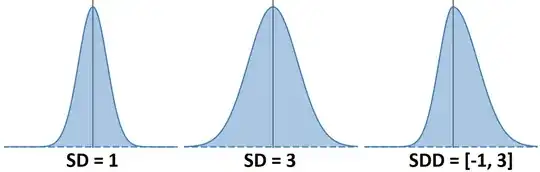
SDD = "standard deviation, directional". For the right-most example, points to right of mean are only a detriment to describing points to left, and the mismatch in distributions can be much worse than shown here (though it does assume "mean" is the right anchor, hence importance of choosing it right).
Formalizing
@IgorF's answer shows exactly what I intended, minus handling of x == x.mean() which I've not considered at the time, and I favor 1/N over 1/(N-1); I build this section off of that. What I dislike about that mean handling is
[-2, -1, -1, 0, 1, 1, 2] --> (1.31, 1.31), 1.31
[-2, -1, -1, 1e-15, 1, 1, 2] --> (1.41, 1.31), 1.31
showing --> SDD, SD. i.e. the sequences barely differ, yet their results differ significantly - that's an instability. SD itself has other such weaknesses, and it's fair to call this one a weakness of SDD; generally, caution is due with mean-based metrics.
If the relative spread of the two sub-distributions is desired, I propose an alternative:
- Replace $\geq$ and $\leq$ with $\gtrapprox$ and $\lessapprox$, as in "points within mean that won't change the pre-normalized SD much", "pre-normalized" meaning without square root and constant rescaling.
- Do this for each side separately.
- Don't double-count - instead, points which qualify both for
> mean and ~ mean are counted toward ~ mean alone, and halve the rescaling contribution of the ~ mean points (as in @IgorF.'s). This assures SDD = SD for symmetric distributions.
- "won't change much" becomes a heuristic, and there's many ways to do it - I simply go with
abs(x - mean)**2 < current_sd / 50
[-2, -1, -1, 0, 1, 1, 2] --> (1.31, 1.31), 1.31
[-2, -1, -1, 1e-15, 1, 1, 2] --> (1.31, 1.31), 1.31
[-2, -1, -1, 3e-1, 1, 1, 2] --> (1.35, 1.29), 1.31
[-2, -1, -1, 5e-1, 1, 1, 2] --> (1.48, 1.19), 1.32
It can be made ideal in sense that we can include points based on not changing sd_up or sd_dn by some percentage, guaranteeing stability, but I've not explored how to do so compute-efficiently.
I've not checked that this satisfies various SD properties exactly, so take with a grain of salt.
Code
import numpy as np
def std_d(x, mean_fn=np.mean, div=50):
# initial estimate
mu = mean_fn(x)
idxs0 = np.where(x < mu)[0]
idxs1 = np.where(x > mu)[0]
sA = np.sum((x[idxs0] - mu)2)
sB = np.sum((x[idxs1] - mu)2)
# account for points near mean
idxs0n = np.where(abs(x - mu)**2 < sA/div)[0]
idxs1n = np.where(abs(x - mu)**2 < sB/div)[0]
nmatch0 = sum(1 for b in idxs0n for a in idxs0 if a == b)
nmatch1 = sum(1 for b in idxs1n for a in idxs1 if a == b)
NA = len(idxs0) - nmatch0
NB = len(idxs1) - nmatch1
N0A = len(idxs0n)
N0B = len(idxs1n)
sA += np.sum((x[idxs0n] - mu)**2)
sB += np.sum((x[idxs1n] - mu)**2)
# finalize
kA = 1 / (NA + N0A/2)
kB = 1 / (NB + N0B/2)
sdA = np.sqrt(kA * sA)
sdB = np.sqrt(kB * sB)
return sdA, sdB
x_all = [
[-2, -1, -1, 0, 1, 1, 2],
[-2, -1, -1, 1e-15, 1, 1, 2],
[-2, -1, -1, 3e-1, 1, 1, 2],
[-2, -1, -1, 5e-1, 1, 1, 2],
]
x_all = [np.array(x) for x in x_all]
for x in x_all:
print(std_d(x), x.std())
{kind=link}