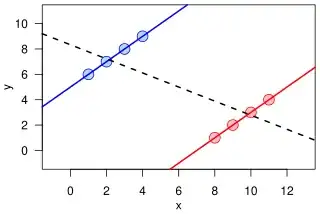
I have a data set with a continuous LHS variable y, continuous RHS variable x, and a dummy D. I am running two OLS regressions: $$y_i=\beta_0+\beta_1*x_i+\epsilon_i$$ and $$y_i=\gamma_0+\gamma_1*x_i*(D_i=1)+\gamma_2*x_i*(D_i=0)+\eta_i$$ My estimated $\hat{\beta_1}$ coefficient is larger than both $\hat{\gamma_1}$ and $\hat{\gamma_2}$, which confuses me. Shouldn't it be the weighted average of the two sample-specific slopes (with positive weights)? The regression samples do not change.
With the Stata code below, I can replicate the result, but I don't have a good intuition of what is happening:
clear all
set seed 1234
set obs 10000
gen x=runiform(0,100)
gen d=x>50
gen y=2-5x+rnormal(0,1) if d==0
replace y=2-2x+rnormal(0,1) if d==1
reg y x
predict y_pool
reg y c.x#i.d
predict y_int
twoway (scatter y x if d==0) (scatter y x if d==1) (scatter y_pool x, color(green)) (scatter y_int x, color(orange)), legend(order(1 "D=0 sample observations" 2 "D=1 sample observations" 3 "Pooled predicted values" 4 "Sample-specific predicted values"))