I'm not sure I understand details of your 'matching' procedure. However, a binomial distribution (with replacement) has larger variability than a corresponding hypergeometric distribution (without replacement). Intuitively, as sampling without replacement depletes the population, the variability of available choices decreases.
Example: Consider the number of red chips in five draws, sampling with replacement (binomial) from an urn with 5 red chips and 5 green chips.
By contrast, consider sampling without replacement (hypergeometric). The
two distributions are plotted below. The binomial standard deviation is $1.1180$ and the hypergeometric SD is $0.8333.$
x1 = 0:5; n = 5; p = 0.5
b.pdf = dbinom(x1, n, p)
x2 = 0:5; n = 5; r = 5; b = 5
h.pdf = dhyper(x2, r,b, n)
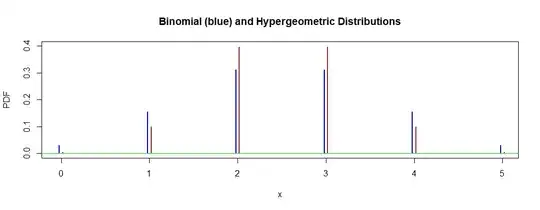
hdr = "Binomial (blue) and Hypergeometric Distributions"
plot((0:5)-.02, b.pdf, ylim=c(0,.4), ylab="PDF", xlab="x",
type="h", lwd=2, col="blue", main=hdr)
lines((0:5)+.02, h.pdf, type="h", lwd=2, col="brown")
abline(h=0, col="green2")
Below each of the experiments is simulated 10,000 times and results
are summarized.
set.seed(2021)
x1 = rbinom(10^4, 5, .5)
summary(x1); sd(x1)
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.000 2.000 3.000 2.515 3.000 5.000
[1] 1.123965 # aprx binomial SD
x2 = rhyper(10^4, 5,5, 5)
summary(x2); sd(x2)
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.000 2.000 3.000 2.497 3.000 5.000
[1] 0.8397981
