That part of the Wikipedia article leaves a bit to be desired. Let's separate two aspects:
The need for nonlinear activation functions
It's obvious that a feedforward neural network with linear activation functions and $n$ layers each having $m$ hidden units (linear neural network, for brevity) is equivalent to a linear neural network without hidden layers. Proof:
$$ y = h(\mathbf{x})=\mathbf{b}_n+W_n(\mathbf{b}_{n-1}+W_{n-1}(\dots (\mathbf{b}_1+W_1 \mathbf{x})\dots))=\mathbf{b}_n+W_n\mathbf{b}_{n-1}+W_nW_{n-1}\mathbf{b}_{n-2}+\dots+W_nW_{n-1}\dots W_1\mathbf{x}=\mathbf{b}'+W'\mathbf{x}$$
Thus it's clear that adding layers ("going deep") doesn't increase the approximation power of a linear neural network at all, unlike for nonlinear neural network.
Also, nonlinear activation functions are needed for the universal approximation theorem for neural networks to be valid. This theorem states that under certain conditions, for any continuous function $f:[0,1]^d\to\mathbb{R}$ and any $\epsilon>0$, there exist a neural network with one hidden layer and a sufficiently large number of hidden units $m$ which approximates $f$ on $[0,1]^d$ uniformly to within $\epsilon$. One of the conditions for the universal approximation theorem to be valid is that the neural network is a composition of nonlinear activation functions: if only linear functions are used, the theorem is not valid anymore. Thus we know that there exist some continuous functions over hypercubes which we just can't approximate accurately with linear neural networks.
You can see the limits of linear neural networks in practice, thanks to the Tensorflow playground. I built a 4 hidden layers linear neural network for classification. As you can see, no matter how many layers you use, the linear neural network can only find linear separation boundaries, since it's equivalent to a linear neural network without hidden layers, i.e., to a linear classifier.
The need for ReLU
The activation function $h(s)=\max(0,cs)$ is not used because "it increases the nonlinearity of the decision function": whatever that may mean, ReLU is no more nonlinear than $\tanh$, sigmoid, etc. The actual reason why it's used is that, when stacking more and more layers in a CNN, it has been empirically observed that a CNN with ReLU is much easier and faster to train than a CNN with $\tanh$ (the situation with a sigmoid is even worse). Why is it so? There are two theories currently:
- $\tanh(s)$ has the vanishing gradient problem. As the independent variable $s$ goes to $\pm \infty$, the derivative of $\tanh(s)$ goes to 0:
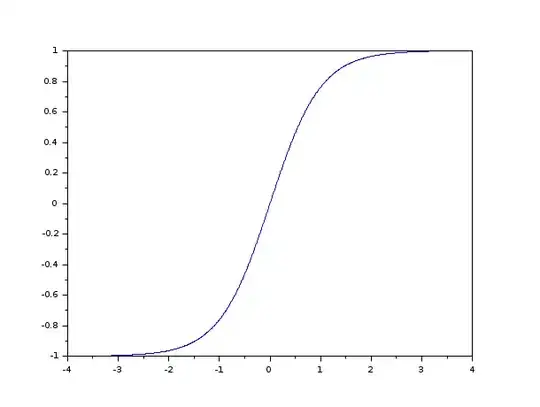
This means that as more layers are stacked, the gradients get smaller
and smaller. Since the step in weight space of the backpropagation
algorithm is proportional to the magnitude of the gradient, vanishing
gradients mean that the neural network cannot be trained anymore.
This manifests itself in training times which increase exponentially
with the increase in the number of layers. On the contrary, the
derivative of ReLU is constant (equal to $c$) if $s>0$, no matter how
many layers we stack (it's also equal to 0 if $s<0$ which leads to
the dead neurons issue, but this is another problem).
- there are theorems which guarantee that local minima, under certain conditions, are global minima (see here). Some of the assumptions of these theorems don't hold if the activation function is a $\tanh$ or sigmoid, but they hold if the activation function is a ReLU.



{kind=link}