I am looking for a way to break this kind of captcha:
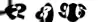
I know that there are always 4 digits, in black and white. The image basically consists of an easily recognizable 4-digit code, mixed with a mask whose form is arbitrary.
I am pretty confident that I will manage to break the image into 4 parts containing the 4 digits. I also know that when we have a digit without mask, it is easily recognizable. But I don't see how to remove the mask...
Do you have any ideas please?
(I am doing this for a study project)