The other answers are good, but I thought that another answer with a slighlty different focus might be a good complement.
Does the sample size usually affect the false-positive rate?
Judging from the comments, I think that the question has been prompted by this article, which includes a couple of mistakes (or at least miswordings).
Firstly (and most worryingly in general) it defines p-values incorrectly, but more relevantly it includes the sentence "If you measure a large number of things about a small number of people, you are almost guaranteed to get a “statistically significant” result."
The p-value is the probability, assuming that the null hypothesis is true, of observing a result as least as extreme as the one that was actually observed. As pointed out in the other answers, this means that it should be uniformly distributed between 0 and 1 regardless of sample size, underlying distributions, etc.
So the sentence should have read "If you measure a large number of things about a small number of people, you are almost guaranteed to get a “statistically significant” result."
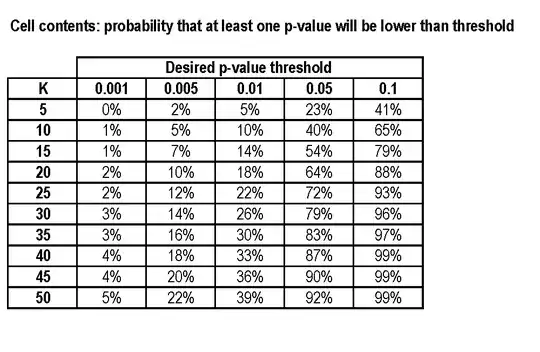
As correctly calculated in the article, even if chocolate does exactly nothing there was a 60% chance (assuming independence, etc.) of getting a significant result.
They actually got three significant results, which is quite surprising (p=0.06 under the -- probably unrealistic -- assumption of independence).
Does the sample size ever affect the false-positive rate?
Actually sometimes it does, though it only really makes a difference if the sample size is really small.
I said that (assuming that the null hypothesis is true) the p-value should be uniformly distributed. But the uniform distribution is continuous, while a lot of data is discrete with only finitely many possible outcomes.
If I toss a coin a few times to check whether it is biased, there are only a few possible outcomes and hence a few possible p-values, so the distribution of the potential p-values is a very bad approximation to the uniform distribution. If I flip it few enough times, it might be impossible to get a significant result.
Here is an example of a case where that actually happened.
So you would have something like "If you measure certain types of things about a sufficiently small number of people, you are never going to get a “statistically significant” result, no matter how many things you try."
Does this mean that you shouldn't worry about the sample size if a result is positive?
No. Some positive results are false positives and some are true positives. As discussed above, it's usually safe to assume that the false-positive rate is fixed (generally at 5%). But a smaller sample size always makes true positives less likely (having a smaller sample size means that the test has lower power). And if you have the same number of false positives but fewer true positives, a randomly chosen positive result is more likely to be false.
@AndréPeseur, I think there is going to be some overlap in topics between our website and cross-validated. I'm of the opinion that econometrics should be on-topic here -- Not a SE pro or anything though. Maybe start a meta post to discuss it further if you disagree.
– cc7768 May 29 '15 at 20:41