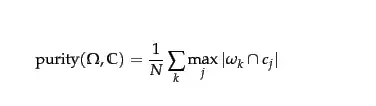Within the context of cluster analysis, Purity is an external evaluation criterion of cluster quality. It is the percent of the total number of objects(data points) that were classified correctly, in the unit range [0..1].
$$Purity = \frac 1 N \sum_{i=1}^k max_j | c_i \cap t_j | $$
where $N$ = number of objects(data points), $k$ = number of clusters, $c_i$ is a cluster in $C$, and $t_j$ is the classification which has the max count for cluster $c_i$
When we say "correctly" that implies that each cluster $c_i$ has identified a group of objects as the same class that the ground truth has indicated. We use the ground truth classification $t_i$ of those objects as the measure of assignment correctness, however to do so we must know which cluster $c_i$ maps to which ground truth classification $t_i$. If it were 100% accurate then each $c_i$ would map to exactly 1 $t_i$, but in reality our $c_i$ contains some points whose ground truth classified them as several other classifications. Naturally then we can see that the highest clustering quality will be obtained by using the $c_i$ to $t_i$ mapping which has the most number of correct classifications i.e. $c_i \cap t_i$. That is where the the $max$ comes from in the equation.
To calculate Purity first create your confusion matrix This can be done by looping through each cluster $c_i$ and counting how many objects were classified as each class $t_i$.
| T1 | T2 | T3
---------------------
C1 | 0 | 53 | 10
C2 | 0 | 1 | 60
C3 | 0 | 16 | 0
Then for each cluster $c_i$, select the maximum value from its row, sum them together and finally divide by the total number of data points.
Purity = (53 + 60 + 16) / 140 = 0.92142